bremap.de
Event Overview for the City of Bremen#
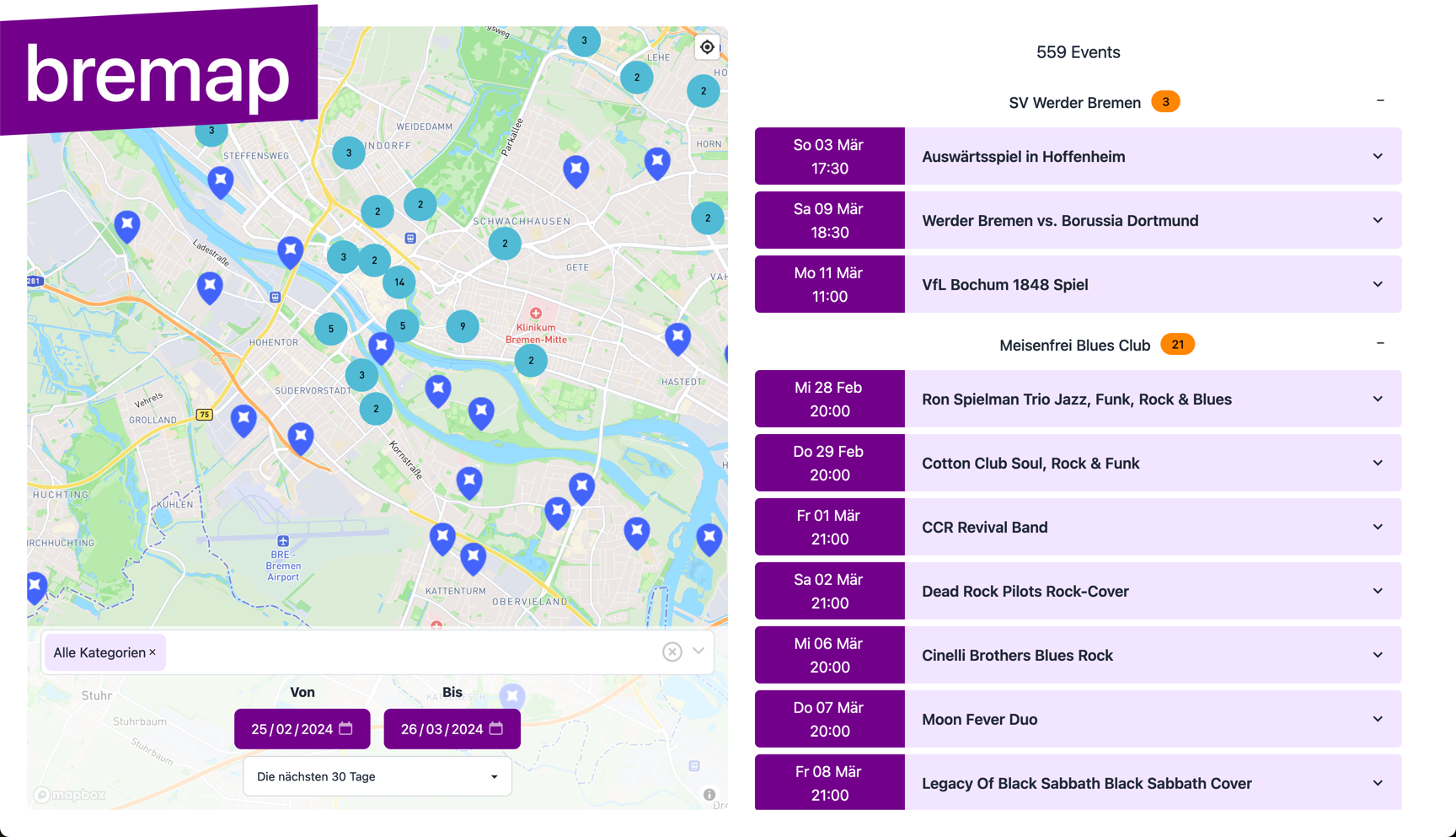
bremap.de searches the websites of over 1500 venues in and around Bremen for events and uses ChatGPT to extract the event data. The final data is then displayed on a map with date and category filters and full text search.
Origin#
This project is sponsored by FOMO (Fear of Missing Out), the power that makes the world go ‘round ;)
After the Covid social distancing restrictions ended, there was a sense of FOMO, with venues opening up again (those that survived), some extending their Covid-time events, local support groups growing into long-term projects, restaurants opening up again with new owners or new concepts.
I guess it has always been the case that discovery for small events has been limited, but it felt more relevant now. I felt like there could be things going on in my neighborhood, even next door, without me ever hearing about them unless I specifically looked for them or learned about them by chance.
My goal was to surface all those little events like flea markets, library tours, food truck stops, pop up stores, basically anything that was local and temporary, often without the resources to advertise their events.
Sourcing Event Data#
Some of these events will be advertised offline only, on flyers and bulletin boards. Some of these events will be walled by social media or only get posted as images (that’s honestly the worst, also in terms of accessibility). Leaving these hard problems aside, I decided to focus on venues that had websites. If there is a decent amount of traffic for the MVP, the pool of event data sources could be expanded.
Where is the Data Coming From?#
OpenStreetMap (OSM) is a crowd-sourced map of the world that has excellent coverage, especially in Europe and North America. Aside from geographic features and streets, there is a treasure trove of information collectivly entered by volunteers. I remember being blown away when I discovered that I could filter the map for drinking water sources, like public faucets or wells. There are more than you would think if you know where to look, and it comes in very handy while cycling and hiking. The volunteers enter all kinds of real world data - park benches, bike racks, traffic lights, historical sites, river crossings and many, many more.
I found this tool that lets you extract all geoinformation inside a bounding box: Overpass Turbo. I exported the data for the area of Bremen as geojson and used Jupyter Notebook to quickly analyze and filter the data. The goal was to filter for places that could concievably host events. Helpfully, OSM has a rich system of tags for places, further subdivided into specific types like leisure:trampoline_park or amenity:nightclub. I went through the lists and hand picked all tags that seemed useful.
Implementation#

Before starting, I looked for prior attempts of sourcing event data from the web and found this paper titled “WebFormer: The Web-page Transformer for Structure Information Extraction” (PDF). The approach by the researchers from Meta and Google was basically training a transformer model on text from the DOM and incorporate the DOM tree with graph attention. Unfortunately, neither model weights nor training data were made available, so I couldn’t even begin trying to replicate the results of the paper.
Thankfully, the “bitter lesson” (PDF) in AI applies to the field of event extraction as well: Scaled up generalist models outperform specially engineered networks. Just throw more compute at it. So when OpenAI announced the ChatGPT batch API, I knew that this would make things much easier for me.
The technical approach I settled on was a pipeline that scrapes websites, finds dates using regular expressions, extracts the relevant text, and then uses ChatGPT to parse out the event information. The key insight here was that every venue website is built differently - some use WordPress event plugins, some have custom calendars, some just have plain text listings. It’s quite impressive with how many ways of presenting dates and times people come up with. My favorite ‘gotcha’ at this stage was dealing with impossible dates, like events scheduled for April 31st (the month of April has only 30 days). Things like this actually raise an error in the date parsing library that I’m using (ctparse), so that was a fun discovery when the scraper suddenly starting erroring out unexpectedly.
After the raw text content has been extracted, it gets stored in MongoDB. Then I send batches of this text to OpenAI’s batch API, which is much more cost-effective than making individual API calls. ChatGPT extracts structured event data (names, dates, locations, descriptions, tags) and returns it as JSON. Before the OpenAI API supported structured outputs, I actually wrote a parser, that tries 3 different JSON parsing libraries to get the ChatGPT responses as JSON. OpenAI supporting structured outputs made this whole mess obsolete. Once I have the structured data, I deduplicate the events and finally store everything in PostgreSQL with full-text search capabilities using ParadeDB.
The frontend is a map interface where you can filter by date range, browse by category, and search through all the events. The search uses BM25 ranking, which works well for finding relevant events and includes tags that we also get from ChatGPT, so you can search for categories like “concerts” or “sports”.
Challenges
The biggest challenge has been dealing with the sheer variety of how venues present their events. Some websites have beautifully structured event calendars with clear dates and times. Others have events buried in blog posts or news sections. Some venues use relative dates like “next Friday” or “every Monday”, which ChatGPT sometimes struggles with. Recurring events are particularly tricky - do you expand “every Monday in March” into individual events, or keep it as one recurring event? I’ve gone with expanding them, but it’s not always perfect.
Deduplication is another ongoing challenge. The same concert might be listed on the venue’s main page, their events page, and maybe even a third-party ticketing site. I compare event names, dates, and locations to catch duplicates, but sometimes events with slightly different names slip through, or the same event gets listed with different date formats.
Cost is also a consideration. Processing 1500+ websites through the OpenAI API isn’t free, especially when some pages have thousands of words of text. The batch API helps a lot with this, offering significant discounts, but it’s still something I need to keep an eye on. I’ve optimized by only processing pages that haven’t been extracted yet, and by limiting the amount of text sent to ChatGPT per page.
Results
So far, the system has been scraping and extracting events from over 1500 venues around Bremen and finding around 8000 events on each run. The types of events it finds are exactly what I was hoping for: small local concerts, community workshops, library events, and all sorts of small scale happenings that would otherwise be hard to discover.
One thing that’s been interesting is seeing how many events are happening that I had no idea about. There are regular meetups, recurring markets, and one-off events happening all over the city that just don’t have the marketing budget to get widespread visibility. Some venues update their websites frequently, others less so, but the aggregation of all these sources creates a pretty comprehensive picture of what’s going on.
Future
There are a few directions I’d like to explore. The obvious one is expanding beyond websites - integrating social media feeds, scraping event listing sites, maybe even finding ways to surface events that are only advertised offline. But that’s getting into much harder territory.
I’d also like to improve the extraction accuracy, especially for dates and recurring events. Maybe fine-tuning a model specifically for event extraction would help, or using a combination of rule-based parsing for common patterns and ChatGPT for the edge cases.
On the user side, I’m thinking about adding features like personalized recommendations, event reminders, or ways for users to submit events that the scraper might have missed. Community curation could be really valuable here.
For now though, I’m happy with how it’s working. It’s solving the FOMO problem, at least for me, and hopefully for others in Bremen too.
I’m also planning to do some curation for a newsletter, that users can sign up now on the home page.